
プロダクトライン開発(Product Line Engineering:PLE)では、バリアント管理を通じて、製品系列で共有する資産を体系的に再利用します。これは派生開発で継続して行われる改善や工夫を、上手に情報管理して役立てるということです。そうすることで、複雑さが増大する製品の開発を加速すると同時に、品質が改善され、トレーサビリティが高度に確保でき保守性も向上するなどの相乗効果も得られます。
再利用の秘訣はバージョンとバリアントの混同を避けること
プロダクトライン開発では、製品系列内で資産を共通要素と変動要素に分類して開発・管理することで、体系的な再利用を目指します。その秘訣は、製品間の違いである変動要素の管理(バリアント管理)に、バージョン管理ツールを用いないことです。
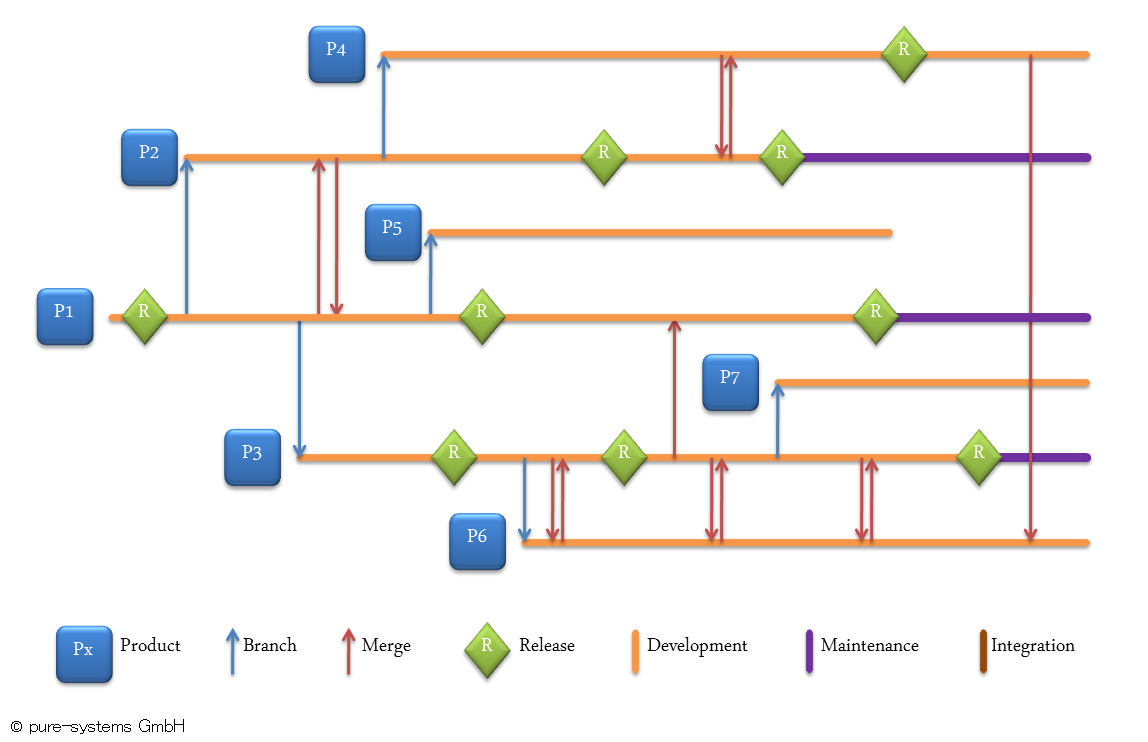
バージョン地獄
上図は、典型的なバージョン管理から派生されるブランチ/マージのログで、複数の製品が既存システムのクローンから独自にメンテナンスされています。この状況では、全てのブランチされたインスタンスに変更を同期させ続けることは非常に厄介であることは明らかです。そして必要になる作業量から、多くの場合2つの製品間のみでマージされることになり(いくつかのパーツを別の製品から取ってくるだけ)、体系的な再利用になりません。バージョン管理される資産の粒度が変動要素と同等で無い限り、バージョン管理内のブランチは変動要素の表現には向きません。そしてファイルの資産に関しては、粒度のミスマッチは全く避けることができません。資産への変更をそのライフサイクルにわたって追跡するために適正なバージョン管理ツールは必要ですが、バリアントの管理を一緒にはできないということです。
再利用の課題
・機能追加で変動要素、依存関係、複雑性が指数関数的に増える
・既存ツールではバリアント管理がサポートされない
・製品開発ライフサイクルを通して資産の体系的な再利用ができない
派生製品の開発で、以下のような苦労をされてませんか?
・コードを再利用するつもりが、同じバグの対応を何度も繰り返すことに
・ブランチとバージョンの組合せ爆発ですべてが複雑になり、メンテナンスも困難に
・メンテナンスコストが増加の一方
・構成管理やビルドプロセスが複雑になり保守が困難
・製品のビルドは熟練者にしかできない
・顧客からのバックポート要求も多い
...
プロダクトライン開発はこのような状況を改善する取り組みであり、持続的な成長を実現するための企業戦略です。
製品間の差異をバージョンではなくバリエーションと捉えることで
バリアント管理という新しいドアが開く
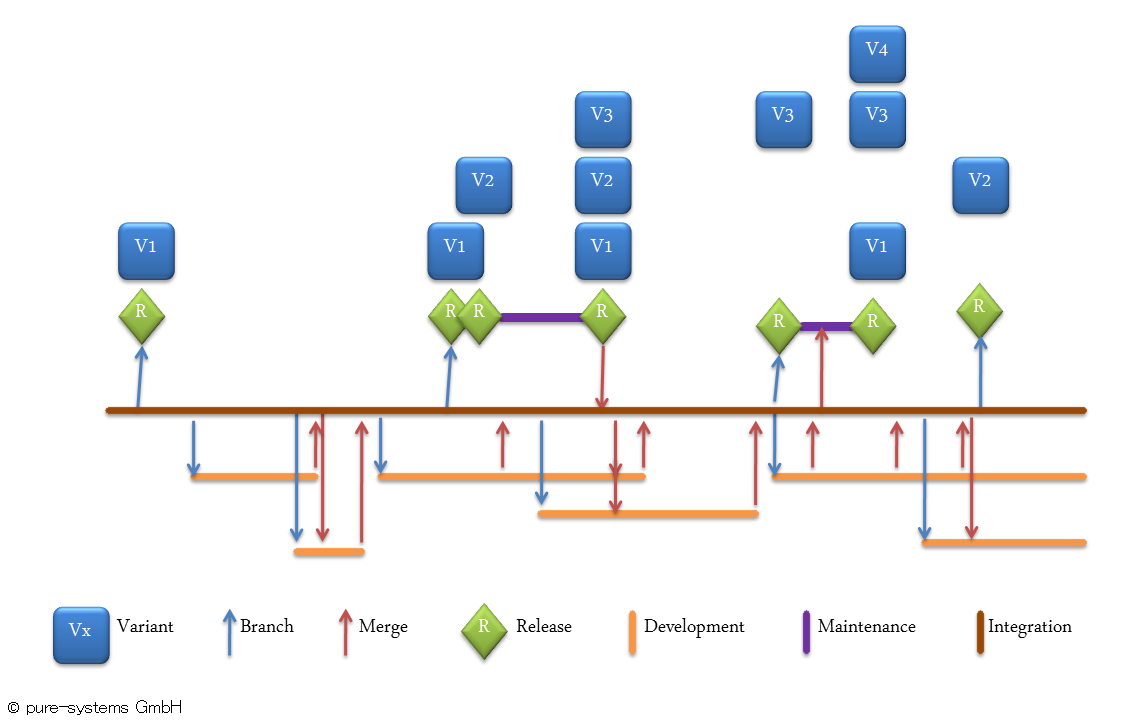
下図は、共有資産から製品バリアントが生産される様子を示します。バリアントの管理は、適正なツールによって独立した活動として実施されるべきです。バージョン管理システムはインスタンスの記録に使われますが、バリアント管理の仕組みは提供しません。
バリアント管理を支援する pure::variants は、欧州車載機器開発の最前線で活用されるなか、顧客の知恵と工夫が機能として組み込まれて進化しています。このバリアント管理支援ツールの開発元であるpure-systems社が、多くの顧客とのプロダクトライン開発の実践を通じて得られた知見を以下に紹介しています。
近年、ソフト/ハード/機械など対象は多岐にわたるようになり、「Software Product Line Engineering」では無く「Product Line Engineering」が用いられています。例えば代表的な国際会議であるSPLCは「Systems and Software Product Line Conference」と、頭に ”Systems and ” が付くようになりました。これに伴い弊社でも、ソフトウエアプロダクトライン開発(SPLE)から、プロダクトライン開発(PLE)に置き換えています。
実践的なプロダクトライン開発について

1.バージョン、バリアント、その他 - 基本的な定義
Article (1) Versions, Variants and all the rest - Basic definitions
プロダクトラインエンジニアリングやバリアント管理の話をする場合、基本的な用語を共通に理解していることが重要です。そして「バージョン」と「バリアント」の区別が最も難解なものの一つだと経験してきました。この二つはプロダクトラインエンジニアリング(PLE)以外の領域では事実上混同して用いられているからです。そのことが原因でしょうか、カンファレンスなどで私どもの展示に訪れる方からよく次のように尋ねられます。「なるほど、何らかのバージョン管理をされているのですね。 xxx(バージョン管理システム名)と比較してどのように違っているのですか?」
以下でバージョンとバリアントに関わる用語について、私が採用している簡潔な定義を行います。そして、それらが誰に関係するのか、同じものとして扱われてしまう理由などを説明します。
資産の一つのバージョンとは、ある時点で記録されたその資産の状態/内容のことです。一つの資産に対する二つのバージョンは、その資産に対する同一の内容であることもあれば異なる内容のこともあります。従って複数のバージョンは一つの資産を異なる時点で反映しているものです。多くの場合、バージョンはラベルや番号で識別されます。リビジョン(構成要素が変更された場合に作られるもの)とバージョン(ラベルや名前付けされたリビジョンを参照するもの)とで相違がつけられることもあります。
‐ベースライン(A baseline)とは、一つの資産群の複数のバージョンの(名前付けされた)一つのスナップショットのことです。
‐バリエーション(A variation)とは、単純に二つの比較できる資産(群)間の相違のことです。
‐バリエーションポイント/可変点(A variation point)とは、一つの資産の異なるバリアントを導く判断を表すものです。一つのバリエーションポイントは(そのバリエーションポイントの正当なバリエーションである)複数の選択可能なインスタンス化から構成されます。バリエーションポイントは通常、インスタンス化に関する判定が行われるバインディングタイムが指定されます。バインディングタイムの例にはコンパイル時、インストール時、実行時などがあります。
バリアントの派生(variant derivation)とは、利用可能な資産群から資産を組み合わせ、含まれるバリエーションポイント群がバインド/インスタンス化されるアクションのことです。複数のバインディングタイムをとるバリエーションポイント群があれば、バリアントの派生はそれぞれのバインディングタイムで段階を追って起こります。そのような派生の結果は派生資産の集合になります。派生は技術的には多くの手段で行うことができ、最も単純な(そして基本的にお勧めできない)方法は、手動で資産群をコピーして(例えばコンフィグレーションのパラメータなど、その一部を)修正することです。そのような派生の結果はコンフィグレーション(a configuration)と呼ばれます。
プロダクトラインエンジニアリングではバリアントの派生が中心的部分となります。これは、プロダクトラインの資産を変更(バグ修正など)すると、多くの場合、変更した資産を含むすべての派生製品を再生成する必要があるからです。この工程を最小限にするために、自動派生をサポートするツールが用いられることが多くあります。
もし資産X’が資産Xから派生していて、同じXから派生した他のバリアント資産とは異なる顧客等の関連属性を持つならば、X’はバリアントを代表します。それらの違いにより同じ資産Xから派生する他の資産群との区別ができます。
例えば、色を塗り分けて青と赤の(色以外の点は全く同じ)ボールを作る機械であれば、青ボールと赤ボールの二つのバリアントを生成できます。このとき、赤か青で塗り分けられるボールの数は問題ではありません。
ここで、バリアントという用語の定義にはバリアントを派生した時点は含まないことに留意してください。バリアントは時間に依存しません。
重要なことは、二つの資産間の小さな相違すべてが個別にバリアントを作るのではなく、製品の利害関係者(顧客など)から見えるバリエーションが個々のバリアントを形成するということです。例えば、最初にシャツを一枚買い、翌週に同じブランド・同じ色・同じ縫製・同じサイズの二枚目を買った場合、もしかすると洗濯ラベルに多少の違いがあったりしても、それはたいした問題ではなくそれらを同じものとして扱うことでしょう(ボロボロになるまでは)。しかし自分用と友達用に違ったサイズのものを購入した場合、それらは(関連するバリエーションが服のサイズである)バリアントです。
ソフトウェアシステムで考えると、一つの資産に対する大部分のバグ修正は新しいバージョンを作りますが、それによって新しいバリアントができるわけではありません。バグ修正によって顧客の観点で望まれ要求される資産の特性が変わるわけではないからです。
最後になりますが重要なのは、バリアビリティ/可変性(variability)はバリエーションポイントによって資産群から得られるバリエーションを表現するということです。可能なバリアント群すべてをリストアップすることは、多くの場合その数が多すぎて不可能なので、フィーチャモデルやコンフィグレーションルールといったバリアビリティモデルを用いてシステムのバリアビリティを表現します。
次の記事では、フィーチャモデルを見て、フィーチャとは何か?についても考えます。
原文:Versions, Variants and all the rest - Basic definitions
2.フィーチャモデルとフィーチャ - フィーチャとは?
Article (2) Feature Models and Features - What’s this?
バリアビリティについてインフォーマルに話すことは面白いのですが、最終的にはバリアビリティの情報を「標準の」方法で捉えることが必要です。もちろん研究や産業界ではそのための多くの方法が考え出されています。様々な理由から、バリアビリティを記録する最もポピュラーな方法はフィーチャモデリング(feature modeling)と呼ばれています。この紹介ではフィーチャモデルのきわめて基本的なコンセプトについて説明します。そして興味深い質問である「フィーチャとは何か?」への答えの手がかりも提供するつもりです。
簡単に言うと、フィーチャモデルはプロダクトラインのコモナリティ(共通性)とバリアビリティを捉えるシンプルで階層的なモデルです。問題空間(problem space)の中の関連する特性がモデルの一つのフィーチャ(feature)となります。この意味で、フィーチャとは利害関係者に関連性があるシステムの特性です。利害関係者の興味次第で、フィーチャは要求や、技術的な機能/機能グループ、または非機能(品質)特性などであったりして、これは悪いニュースです。フィーチャモデルはコモナリティとバリアビリティを記述するための抽象的な概念です。何がフィーチャかは各プロダクトライン個々に決定する必要があります。しかしながら一般には、フィーチャは実際の実装コンセプト(すなわち解決空間= solution space)からある意味切り離されて定義されています。例えば、自動車の色がフィーチャであれば、それは立派な名前(ダークマリンブルーとか)を持つでしょうが、その色の特定メーカーに対する注文番号は(解決空間である)ここでは言及されません。これはソフトウェアでも同じです。あるフィーチャが一つの関数にマップされていようが何十ものコンポーネントに展開されていようが、ここでは関係ありません。もし利害関係者が、それを関連する特性とみなし、それがバリアビリティに相当するならば、それは一つのフィーチャとなるべきものです。
フィーチャモデルはフィーチャの集まりがノードを形成するツリー構造です。フィーチャのバリアビリティは、ツリーのアークとフィーチャのグルーピングで表されます。最近のほとんどのフィーチャモデリングのアプローチでは、次の四つの異なるタイプのフィーチャグループが利用可能です:「必須(mandatory)」、「選択(optional)」、「代替(alternative)」、「一つ以上(or)」。各フィーチャは複数のフィーチャグループを子として持つことができます。バリアントにどのフィーチャが含まれるかを指定するとき、以下のルールが適応されます:もし親フィーチャがバリアントに含まれるなら、
- そのすべての必須の子フィーチャも必ず含められる (「nからn」)。
- いくつでも選択のフィーチャを含めることができる (「nからm、0≦m≦n」)。
- 一つだけフィーチャが、代替のフィーチャグループから選択されなければならない (「nから1」)。
- 少なくとも一つのフィーチャが、一つ以上のフィーチャグループから選択されなければならない(「nからm、m≧1」)。
明らかに「選択」や「代替」などの用語は、グループから有効に選択されるフィーチャの上下限を指定することによって表現される集合のカーディナリティの概念にマップされます。これら四つが最も一般的に用いられています。これらの用語の概念は正確な定義を読まなくても一般的によく理解されています(「一以上」のフィーチャグループは「代替」と混同されがちですが)。
たいていのアプローチは追加の制約も指定できます。フィーチャ間の排他関係(「素敵なシャツ」と「ピンクのシャツ」は対立する)や、要求関係(「素敵なシャツ」は、「白色シャツ」か「黒色シャツ」のいずれかを要する)といったものです。これら制約はツリーを(複数のフィーチャモデルを用いている場合はモデル間さえも)横断します。アプローチとツールに依存しますが、このような制約を表現する言語には専用のものから一般に利用可能なXPathやOCLなどまで表現力と複雑さが違った選択肢があります。しかしながらそのような制約は控えめにするべきでしょう。制約が多くなるに従い、モデル内のコネクションを視覚化し理解することは人間には困難になってきます。
いくつかのアプローチではフィーチャカーディナリティと呼ばれる概念をサポートして、多重のルールをフィーチャモデルのサブツリーで表現することができます。例えば複数の設定可能なセンサーがあるシステムの場合、各センサーのフィーチャの(同じ構造の)サブツリーを個々に作るよりも、センサーを一つ記述して [1-3] のようなカーディナリティを与えて、最小1から最大3のセンサーのサブツリーを選択するようにできます。フィーチャカーディナリティとそれに関連する課題については今後紹介します。章末のRead OnセクションにあるKryzstof Czarneckiの論文を読むことをお勧めします。
フィーチャモデルに対する標準のグラフィカル表記は残念ながらまだなく、多くの異なる表記が存在しています。文献ではFODA(Feature-Oriented Domain Analysis)法のグラフィカル表記の拡張形式が最も一般に使用されていますが、これは標準のテキストツールとグラフライブラリーからなるもので、ただ難しいだけですので、よりシンプルなものが望まれるでしょう。
フィーチャに対する上述の(非常に)抽象的な定義ではすべてのものがフィーチャとなり得、そしてこのことはある意味で正しいことです。そこで、何がフィーチャか、それからどのフィーチャをフィーチャモデルに選択するか、をどのようにして見分けるか? が問題となります。
ここで最も重要な作業は、そのフィーチャモデルが作成される利害関係者を明確に定義することです。フィーチャがプロダクトラインのエンドユーザーに、そのプロダクトラインから派生される彼ら自身の製品インスタンスを定義するために使用されるなら、それらフィーチャはそのエンドユーザーに対してわかり易くなければなりません。良い例は、たいていの自動車メーカーのウエブサイトで昨今提供されている自動車の構成ツールです。またフィーチャモデルの構造はエンドユーザーの考え方に沿っているべきでしょう。
簡単に聞こえますが、実際にこれを完璧に行うことは非常に困難です(正直無理でしょう)。多くの場合、ユーザーのタイプによってシステムの構成の異なるアプローチがあります(特別な小さなフィーチャを探しているのか、自動車のエンジンタイプやサイズ、色などといった一般的な決定を行っているのかというタイプです)。一般にフィーチャモデルは自由にナビゲーションできる(決まった順番でフィーチャを選択することは必要ない)のですが、より一般的な決定はモデルのツリーのよりルート付近でなされる傾向があり、そのことはユーザーをツリーのより深い部分へと導くことになります。
それで、もし利害関係者間で「言葉」が違っていたらどうでしょう? 利害関係者のグループごとに複数のフィーチャモデルを作りましょうか? あるいは、最も重要な(どれになるでしょうか)グループに一つだけ作りましょうか? ここにも明解な答えはありません。依存関係が小さくてシンプルなほどよいでしょう。多くのプロダクトラインアプリケーションにとっては、一つのフィーチャモデルが良い選択となります。しかし、プロダクトラインの部品群で個別のプロダクトラインを形成するなら、複数のフィーチャモデルはもはや必然となるでしょう。設定変更可能なミドルウエア上で走るアプリケーションを考えた場合、ミドルウエアのバリアビリティは、アプリケーション開発者が用いる言語で表現される必要があり、そのミドルウエアを用いるすべてのアプリケーションで同じフィーチャモデルを使うべきです。明らかに、このケースではアプリケーションドメインのバリアビリティとミドルウエアドメインのバリアビリティとのマッピングが必要です。このマッピングを作ることはアプリケーションプロダクトラインエンジニアの役割です。ミドルウエアが唯一の特定コンフィグレーションで使用される場合は、マッピングがまったくないかもしれません。それ以外はかなり複雑となります。例えば、アプリケーション層にセキュアとノンセキュアなアプリケーション動作の選択がある場合、あるミドルウエアのフィーチャ(暗号化サポートや、証明書による認証、SSLプロトコルのサポートなど)は「セキュアなアプリケーション動作」のフィーチャを選択する時には有効にされる必要があります。(モバイル機器向けの認証管理アプリケーションがないために)認証サポートのない携帯電話でアプリケーションが走るならそうでないかもしれませんが。
考慮すべき他の側面はフィーチャの粒度です。もしフィーチャが粗い粒度のバリアビリティのみを表現するなら、有効な構成による個々のインスタンスは恐らくシステムの詳細を十分に表現できないでしょう。細かすぎる粒度では、管理されるフィーチャが増大し、そして複雑性も増大します。ここで再び、背景は何かを考えます:製品構成の自動化には、製品ロードマップの企画と検討よりもずっと高度な詳細化が求められます。そして後から詳細を追加するほうが、モデルからフィーチャを削除するより容易だということです。
経験では、良いフィーチャモデルを得る簡単な方法は、とにかく一つ作ることから始めて、それを用いてプロダクトラインの既知/想定できる製品バリアントを記述してみることです。たいていの場合、瞬時にいくつかの決定はそんなに賢くないことがわかります。選択されたフィーチャがバリアビリティを(詳細レベルで)十分に表現しないこともあります。あるいは、オプションAはフィーチャBの子供として用意されているのに、Aが選択されたときに親フィーチャであるBが選択されてはならない時もあるなど、ツリー構造が間違っていたこともあります。
しかし、これらの間違いは次への糧になります。多くの場合、問題なのはフィーチャそのものよりは構造でしょう。
フィーチャとフィーチャモデルについてはまだあり、以降で紹介します。
一つ言い残しがあります:プロダクトラインのバリアビリティを表現するには、フィーチャモデルが非常に重要な要素であると考えていますが、フィーチャモデルのみでは十分ではないケースがあり、さらに手段としてフィーチャモデルを取るべきではないケースもあります。もしバリアビリティがどちらかというと合成的なタイプだとすると、形式的規則で組み合わされる多数の基本要素(家を建てる時のレンガをのイメージです)があります。これらの規則では無制限のブロックの使用が可能です。この場合、フィーチャモデルではこのことを効率的に表現できないでしょう。しかし(色、材質とか)レンガの取り得るプロパティなら、フィーチャモデルは可能なバリアビリティを上手に表現できるでしょう。そしてフィーチャモデルがベストな選択というケースが非常に多くあります。
Read On
A short paper explaining different feature model notations (FODA, Czarnecki-Eisenecker, FeatuRESB, …)

さまざまなフィーチャモデルの表記法(FODA、Czarnecki-Eisenecker、FeatuRESBなど)を説明した短い文書:グラフィカルな表記を忘れがちな方へのよい参考になります。
Feature Models are Views on Ontologies
Kryzstof Czarneckiらによる論文で、フィーチャカーディナリティなど基本や先進のフィーチャモデリングの概念とオントロジーの領域での関連事項を紹介しています。オントロジーについて興味をお持ちでなくてもフィーチャモデリングの部分は読む価値があります。
Software Product Line Engineering with Feature Models

私がSoftware Acumen社のMark Dalgarnoと書いたもので、実例でのフィーチャモデルを用いたプロダクトラインの入門となります。
原文:Feature Models and Features - What’s this?
3.現状を知る:プロダクト関係のパターン
Article (3) Knowing where you are: Product Relation Patterns
現状の開発アプローチから、(ソフトウェア)プロダクトラインアプローチへの興味をお持ちでしたら、その移行に際して、そして移行中に対する多くの考察があります。簡単な確認で、現状を理解し移行方法を知ることができます。この資料では、製品間の関連パターンと、それによるプロダクトラインへの移行策の関わりについて紹介します。
プロダクトフォレスト
製品はたいてい個々に独立して開発されていますが、共有する機能群があります。それら製品の問題空間(problem domain)は、全てが(違う方式で)エアコンの制御をするといったように、非常に似ています。この場合、それら製品はプロダクトフォレストを成すと呼んでいます。UIウィジットや数学関数集のような(アプリケーションロジックを共有しない)基本ライブラリを共有することは再利用の基本形としてすでに行われていることでしょう。このパターンは、似たドメインをもつ異なる顧客に対して複数のプロジェクトを独立かつ同時に進行させる場合によく見受けられます。下図のように(P0~P3)の製品が時間とともに登場し、変更やバグフィックスなどにより(P’0~P’’’1)のように進化する様子がわかります。

プロダクトフォレストの他の例は初期のMicrosoft Officeです。含まれるアプリケーションであるExcel, Word, PowerPointは基本コンセプトを共有した強く関連する製品としてセットで販売されましたが、それらは全く異なったコードをベースにしていました。これらアプリケーションが似たように振舞うのに、同一ではないという印象をもった経験が多くおありでしょう。このようなすれ違いを感じる振る舞いこそ、プロダクトフォレストで出くわす主要な問題なのです。時間の経過とともに製品間で一貫した振舞いを確保することはより難しくなります。そのことで(製品ごとに個別の対処と知識が求められるので)サポートとメンテナンス費用が次第に増大することになります。また、同じ会社の製品ということで同一感を求めて購入した顧客の満足度を下げることにもなります。
プロダクトブッシュ
プロダクトブッシュでは製品間の結び付きがより強くなります。そこでは製品が共有する原型があり、それを複製して個々の製品が開発されます。新製品は基本的にまず既存製品をコピーし、それに対して、新規あるいは変更された要求が満たされるように開発(というより微調整)されます。

プロダクトフォレストでは時として共有は全くありませんでしたが、このパターンでは何が問題でしょうか? 新製品のための適切な原種を選択するだけで(最小のコストや時間などで新製品へ発展させられるという)とてもよいプランであるかに思え、そうであることもあります。コピーに多くの時間はかかりません。必要なツールも「copy」だけで無料です。ここでは「クローン」に要する部分は安く上がります。しかしながら、このアプローチは初期段階では良く見えても、後から「独自」部分にしっぺ返しをくらうことになります。例えば、P0の顧客が「旧製品」P0と「新しい」P1のフィーチャを統合したものを希望したような場合です。個々に進化を遂げてきたシステムのコードをマージしようとした経験があるなら事の重大さを良くおわかりでしょう。大抵はそこまで到達することが大仕事なので、必要な機能のコンビネーションを改めて実装するほうが安く上がるでしょう。もしプロダクトブッシュが長期にわたって発展していて、バグ対応が多くの製品に反映されている場合、これは悪夢となるでしょう。
数百・数千に枝分かれしているプロダクトブッシュを見たことがあります。もしその枝分かれの様子を描写すれば、ペンの使い方を学んでいる子供が描くようなランダムな絵になるでしょう。そのようなものを正しく理解し、メンテナンスすることはできません。
しかし、どのような場合でもプロダクトブッシュは問題であるとも言えません。長期に亘るメンテナンスの必要が無く、同時並行で開発される製品があまりない(主に一つの開発が終わってから次の製品開発をするような)場合や、新製品が必ず旧製品の機能のスーパーセットを持っているような場合であれば、プロダクトブッシュで上手く運用できるでしょう。
プロダクトブッシュのシナリオが使用されていて、なぜブッシュなのかと思われたら紙にプログラムや製品間の関係を描いて見ると良いでしょう。
プロダクトギャング
次のレベルの製品間の関係はプロダクトギャングです。再利用資産の構成と誂えで製品群が構築されます。再利用の意味する所は、新製品に対して再利用資産を組合せて新製品に新たに必要となる部分を開発できるようにするということです。再利用資産(ここでは「プラットフォーム」:PFと呼びます)に対する変更は、アプリケーションの開発者が新しいバージョンのPFを取り入れるまで製品には反映されません。プロダクトギャングにおける製品群は、より多く/大部分の資産を共有し、それらはプラットフォームの資産から技術的に派生したものです。それ故、製品はプラットフォームのインスタンスであり、ここでは製品という代わりに先の図にあるように、製品バリアント(PV0~PV3)と呼ぶことにします。バリアントとバージョンの定義に関しては、本資料の1.バージョン、バリアント、その他 - 基本的な定義で紹介しています。

高度に構成可能なアプリケーションフレームワークや再利用コンポーネント上に構築される製品群など、どのようなものでも基本的に現状の多くの「再利用」ベースの開発アプローチはこれに属するでしょう。「これはかなりよいと思うけど、何か問題でも?」と尋ねられるかもしれません。確かにプロダクトギャングは、再利用に関して他の二つより良さそうですが、本当のプロダクトラインに対して何か足りません。まさしく現実世界のギャングのごとく、全メンバー間には強固な繋がりが存在しています。しかし、秘密:誰も自身のことをギャングの他のメンバーに明かさないということ、も存在するのです。そしてこのことが、このアプローチの根本的な課題なのです。すなわち、ギャングのメンバーに対する情報が全くかそんなに多くないので、共通資産に対する変更の影響を見積もることは困難で、また、その調整も非常に厄介だということです。例えばコンポーネント内のインターフェース方式を変更する必要がある場合、他のアプリケーションから呼び出されることがないことを確認できるとよいのですが、ギャングのメンバーは個々に(別のブランチで、あるいは異なったバージョン管理ツールのリポジトリで)進化しているので、そのようなことを確認することは容易ではありません。一般に、プロダクトギャングのメンバーに提供される再利用部品の用法に関する情報が十分にない場合、非常に控えめな想定しか出来ないでしょう。このような場合、多かれ少なかれ全メンバーが現状のやり方で利用しているかもしれないことを想定しなければならず、それが変更を非常に複雑にしているのです。そして変更された場合には、それを用いる全メンバーで正しく動くことを検証できるといいのですが、そのためには変更をリリースする前に少なくともギャングメンバーを選択してテストをする(あるいは他の手段によって取り得る全てのケースを確認する)必要があります しかしそれは、異なった製品に対する少しだけ違うビルド処理、他のプロジェクトのリポジトリにアクセスできないこと、あるいは単に時間上の制約から、たいていの場合不可能です。そして製品個々のソリューションのほうが影響が局所的で好まれることから、再利用はやがて低減されることになります。
プロダクトファミリー
最後のパターンは、おおよその最終目標となるプロダクトライン開発:プロダクトファミリーです。前述のプロダクトギャングとの主な違いは、開発組織全体で製品ファミリーのメンバー(PV0~PV3)に対する知識が得られることです。プロダクトファミリーのアプローチでは、製品ファミリーの資産が進化する中で全ての関連製品に対する継続的な管理もされ得ます。共有資産に変更があった場合、すべての時点で(その時点で関連する)ファミリーの全てのメンバーがそれに関わることになります。これはもちろん技術的なプロセスのみならず、資産や製品(バリアント)の個々の担当者間における変更の検討/優先順位付け/却下というコミュニケーションも関わります。

再利用可能なコア資産とそれからなる製品との間の双方向のリンクこそが、プロダクトラインでの再利用と「従来型の」再利用アプローチとの根本的な違いです。もちろんこれは、ただ何もしないで得られるわけではありません。大規模なファミリーを抱えておられるのなら、このことは想像できるかと思いますが。
次のステップ
すでに紹介してきた全てのパターンにはそれぞれのユースケースがあり、どれも常に「問題」と言うことではありません。しかしプロダクトラインということであれば、それはプロダクトファミリーしかありません。そして要は、どのようにして他のパターンからプロダクトファミリーへ移行できるかです。これには基本的に二つのシナリオがあります。その一つは、多くの場合個別に開発される製品群個々がスタートポイントとなるので「Separate Product Merger」と私が呼ぶものです。既存製品間で共有されるものは共通の問題空間(problem space)へのメンバーシップですが、解決空間(solution spaces)は全く依存関係がないか少なくともある程度の逸脱があり、解決空間のマージに努力をかけすぎることになります。しかしながら、なにはともあれ、一つか二つ程度の製品の解決空間の資産を新しいプロダクトラインのベースとして用いることを考えることです。例えば、一つか二つベストな製品、最もシンプルなものか最も複雑なもの、を選択します。
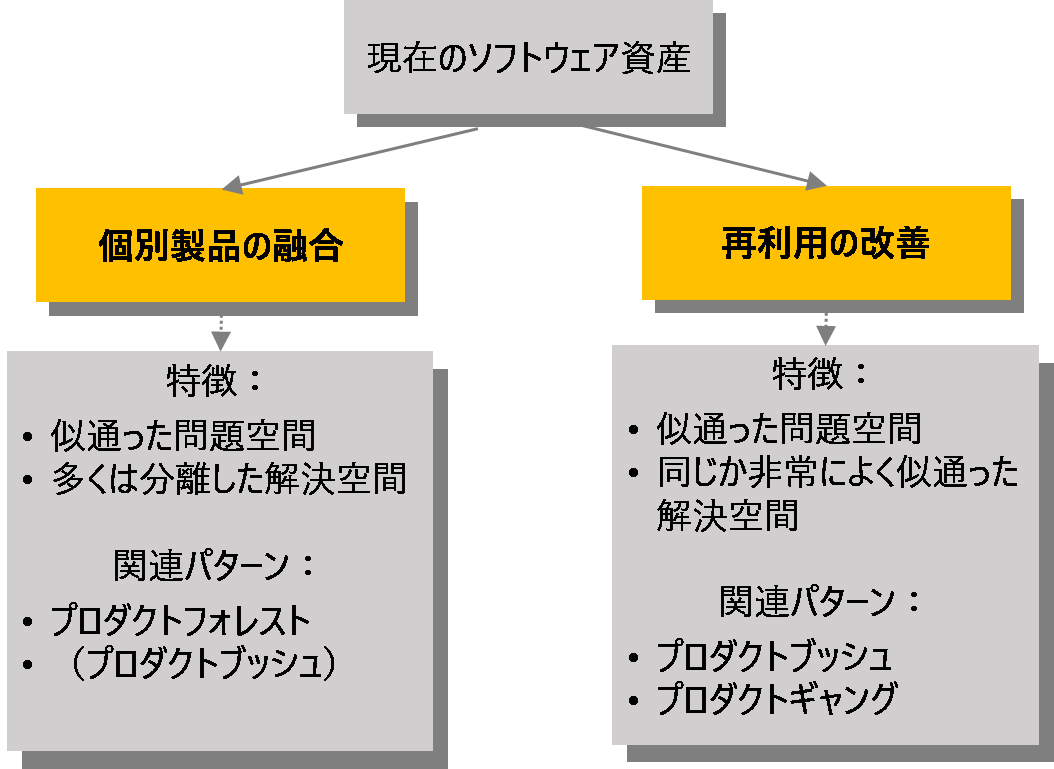
プロダクトブッシュやプロダクトギャングでは再利用は既に行われています。それゆえ、私はもう一つのシナリオを単純に「再利用の改善(Reuse Improvement)」と呼んでいます。問題空間も解決空間の資産も多くの既存資産に密接に関係するので、多くの既存資産が新しいプロダクトラインで用いることができます。多くの場合、この再利用改善シナリオでのゴールの一つは、全ての既存製品が新しいプロダクトラインの資産から大体変更することなく生成できるようにすることです。このシナリオでは最初に何を解析するかの選択があります。シンプルで直ぐにかかれるアプローチは、解決空間のバリエーション(コードレベルで比較してマージすることなどによる)から始めて問題空間のバリエーションへと繋げることです。もう一つのアプローチは、問題空間から始めて解決空間へと進むことで、これはプロダクトライン開発をスクラッチから開始するのと同様のものです。この場合、問題空間のバリエーションを解決空間に存在するバリエーションにマップすることは容易ではないので、問題空間と解決空間のマップは、より複雑なものとなります。しかしながら、このアプローチは「Separate Product Merger」シナリオでも多かれ少なかれ必須な作業です。
バリエーションポイントを解析して問題空間と解決空間をドキュメント化することは容易な作業ではないので、改めて紹介します。
原文:Knowing where you are: Product Relation Patterns
4.変化するターゲット ― プロダクトラインの変更管理
Article (4) Moving targets – Change Management for Software Product Lines
ここでプロダクトライン開発における変更管理について紹介します。これは挑戦しがいのある話題であり、多くの場合、製品群の構成よりもプロダクトライン開発の成功に関して重大なものです。プロダクトラインは生物のように変化し続けます。プロダクトライン開発について聞きかじった人の多くは、それは慣れ親しんだ通常のソフトウェア開発よりずっと複雑だと信じています。驚くことに、プロダクトライン開発は多くの側面で従来方式の開発に非常に似ています。両者の主な違いは同時に配慮するべき製品の数によってもたらされ、そのことが疑いも無しに複雑性と重要課題を追加しているのです。
変更のソース
プロダクトラインへの変更要求や変更には非常に多くの異なるソースがあります。一つのソースは製品から出た欠陥です。欠陥はすぐに除去する必要がありますが、ビジネス上で関係する、すなわち出荷済みか開発中で、欠陥の影響を受ける製品群へのインパクトを見積もることが非常に重要です。ここでは迅速であることがキーであり、即座に(そして正確に)インパクトを見積もることでのみ、適正な決定(いつ、どのようにして、プロダクトラインのどの製品群の欠陥を直ぐに修正するか、後回しにするか、しないか)を行うことができます。
変更の二つ目のソースは新製品のアイデアです。多くの場合、GPS受信機付きの携帯電話でナビゲーションアプリケーションをサポートするといったようなアイデアはマーケティング、製品管理、あるいは顧客からもたらされます。そして、この例ならハードウェアの変更とドライバソフトウェアなど、アイデアのために新しい機能がプロダクトラインへ統合される必要があります。しかし多くの場合製品のアイデアは、既存の機能と要件との新しい組み合わせ(ビジネス電話にMP3プレーヤーとFMラジオアプリケーションといった)を求めるのみです。
テクノロジーの動向(携帯電話のタッチ画面操作のような)は、この点で異なります:もたらされる変更が、非常に大きなインパクトをソリューションスペースと同様、プロダクトライン内の利用可能なフィーチャや要求、他の情報に対して与えることになるので、プロダクトラインに新しい技術トレンドを取り込むことを考えるには多くの時間を割くべきであり、それゆえ一つの技術トレンドがプロダクトラインについての既存の情報へ多大な変更をもたらし得るということです。
変更管理の重要課題
プロダクトラインの変更管理の主要な課題はどこにあるでしょうか? 変更のインパクトが単一の製品開発に比べて高いということは明らかです。変更が市場に出荷された製品や開発中のものにまで影響を与える可能性があるからです。変更によってもたらされる一つの問題で多くの製品が影響を受けることもありますが、一つの修正で影響を受ける全ての製品の修正となるという逆のケースもあります。いずれにせよ変更によるインパクトは増加するので、より注意深い扱いが求められます。一つの変更が多くの資産にインパクトを及ぼすだけでなく、一般には各共有資産に対してより多くの変更要求があります。多くの利害関係者が関わることになるので、単一の製品開発で同じか似た資産を使用することに較べてより多くの変更要求がなされる可能性が高いです。これには「両立しない」変更を求める変更要求が含まれることもしばしばです。それらが変更管理プロセスで正しく扱われないと変更要求の確認に追われて、実装やテストなどを終えるどころではなくなってしまいます。
しかし、それでも欠陥や問題の数は、単一の製品の資産を開発することに比べて同等か、あるいはいずれ減少することになります。理由は簡単で、問題の数はコード行数に関係するからです。共有されるコードは、(バリエーションのため)共有しない単一の製品用のコードに比べて大きくなりますが、その増加はたいてい穏やかな傾向です。そして共有されるコードは、より良くテストされ、より堅牢です(より多くの「稼働時間」で問題が明らかになります)。結局のところ、これで問題が少ない良いコードというプロダクトライン開発の効果を得ることができるのです。あるケースではプロダクトラインのやり方で部品をマージして共有することで、プロダクトラインに関する問題を全体の10%に削減しています。
変更の速度を管理することは難解で興味深い課題です。共有資産への新機能や修正をできるだけ早く必要とするプロジェクトもありますが、共有資産の変更ごとに全製品の再テスト/再リリースが伴うので、頻繁には変更されないという高い安定性を望むプロジェクトも多いのです。このような利害関係は完全には避けようが無く、妥協が必要です。プロセスや採用される技法はできるだけこのような課題を緩和できることが必要です。利害関係者が増えるということも別の意味で複雑になる要因です。このことでPLEアプローチの成果を失わないために、上手な意思疎通と協調が必要になります。
最後に、意思疎通と情報交換のインフラ作りが大切だということです。プロダクトライン開発では全ての利害関係者がプロダクトラインの全ての関連情報(要件、テスト結果、変更要求、バリアント定義、フィーチャモデル)に、バージョン管理システムにある共有コードと同様に簡単にアクセスできることが非常に重要です。それには中央集権で統一された情報管理が求められます。市販され企業で使用されているほとんどの要件/変更の管理/テストツールは、それだけではプロダクトライン開発を十分に支援するようにはできていません。それゆえ通常、要件/変更要求を保守するための要件/変更管理ツールと、バリアビリティやバリアント情報を保守するためのプロダクトラインを支援するツールが必要になるでしょう。これらデータベースの情報は継続的に変更されます。そして、この情報でさえも場合によっては十分ではありません。アーキテクチャ図や顧客の要求・要望などの補完的な資料へのリンクもあったりします。これら全ての情報はプロジェクトマネージャやアーキテクトなど異なる利害関係者に応じた、異なった見え方で提供する必要があります。例えばあるプロジェクトの開発者は、自身が関わる要件と機能についてのみ知りたいだけでプロダクトラインの全機能を知りたいのではありません。プロダクトラインマネージャなら異なる製品バリアントの比較や、共有フィーチャの特定グループに対する変更要求に関する状態などに興味を持つかもしれません。プロダクトラインの情報モデルは、利害関係者ごとに関連するビューを生成して、それぞれのタスクが、単一システムの開発に比較して、大きな負荷がなく高品質で実施できるようにされなければなりません。
プロダクトラインに関わる変更で変更方法に顕著な違いがあることは明らかですが、製品固有の課題や変更要求は通常の単一製品の開発に対するものと同様に扱えます。
正しく理解すること
PLEにおける変更管理に銀の弾丸はありませんが、プロダクトラインの変更プロセスをどのように行うかのアイデアを、その役割や組織上の構成の点から紹介します。
PLEに特有の変更管理の複雑さに対応するためには、組織上特有の要求、変更管理に対する製品市場や顧客の要望、その他多くを打ち合わせるための適正な基盤をお膳立てすることが必要となります。しかしながら基本は多くの実績あるアプローチとほとんど同じです。例を用いて変更管理の役割とプロセスを説明します。コア資産を提供するプラットフォームがあり、製品プロジェクトでそれらコア資産を使用する複数のものがあると仮定します。それら個々のプロジェクト全てやプラットフォーム開発の管理は、プロダクトラインマネジメントオフィスによって管理されます。このオフィスに必須の役割はプロダクトラインマネージャで、プロジェクト間のレポートや査定などのプロダクトラインのタスク同様、プラットフォームとプロジェクトを協調させるもので、基本的に全ての意思決定のトップとなります。他の重要な役割にプロダクトライン品質マネージャがあり、全ての開発物の品質を管理・保守することに責任を持ちます。これはプロダクトライン開発に特有の役割ではありませんが、当然ここでは重要です。ドメインエキスパートは問題空間とその具体的な解決空間へのマッピングに必要となる知識を提供します。
この筋書きでは変更要求は一つの変更管理委員会によって取り扱われます。この委員会は全プロジェクトとプラットフォームの上に位置します。これがなぜそんなに重要なのか? もし変更要求が先にプロジェクト内で対処されてから、プロダクトラインに重大と考えられるものだけが変更管理委員会に送られるとすると、a) 少なくとも他のプロジェクトが重大な課題を認知するまでに遅延が生じる、b) 関連するかもしれない多くのトピックが変更管理委員会に全く知らされなくなってしまう。このような管理体制は通常あまり上手く行きません。プロダクトライン変更管理委員会は、純粋に単一の製品のみの問題はそのプロジェクトに即座に一任しながらも、複数製品やコア資産にインパクトをもたらす全ての変更は管理しなければなりません。
変更管理委員会が得られるデータ(=変更要求)のフィルターとなる一方、アーキテクチャレビュー委員会が、アーキテクチャが常に安定してすべてのプロジェクトで活用できると確かめることを受け持ちます。一般には製品の進化によりコア資産も進化していく必要があるので、この業務は継続するものです。アーキテクチャガイドラインやパターンなどの記述もアーキテクチャレビュー委員会の業務です。基本的に、アーキテクチャレビュー委員会は解決空間の実装を管理します。
最後に重要なものに、プロダクトラインマネージャとプロジェクトマネージャで構成されるプロダクトライン管理委員会があります。それは、プロダクトラインに影響する戦略的決定-プロダクトラインのスコープの定義やプロダクトライン組織構造の決定、製品開発の優先付け、その他(高レベルな)事項について、責任を負います。実際、製品スポンサーもプロダクトライン管理委員会に関与することができます(上述の役割を負わなければ)。製品スポンサーはユーザーや顧客を代表することになります(ですので、この役割がプロダクトマネージャと呼ばれます)。いくつかの決定にはドメインエキスパートも関与するでしょう。しかし、プロダクトライン管理委員会はコンセプトの事項についてよりは、プロジェクトの作業を調整することが目的なので、通常はマネージャやスポンサーのみで担われます。
ドメインエキスパートは変更管理委員会に関与して、ドメイン内の変更の一貫性を保ち、異なるソースからの変更要求をまとめて再利用の最大化と重複作業の最小化に努めます。可能なら、変更がプロダクトラインの戦略に影響しないことを確認するため製品スポンサーが変更管理委員会に関わるべきです。アーキテクチャレビュー委員会には、テクニカルアーキテクトや場合によってドメインエキスパートが関与します。開発者だけが(幸か不幸か)、これら委員会に関わることはないのです。
これら委員会はいつもあるわけではないので、その間を取り持つような作業者も必要となります。プロダクトライン管理委員会の一部として、PLEタスクフォースがプロダクトライン開発を運用する日々の業務を担います。深刻な課題が浮上した場合、タスクフォースが個々の委員会に通告します。このタスクフォースは、ドメインエキスパートや、テクニカルアーキテクト、場合によってはビジネス上のドメインエキスパートや製品個々のエキスパートで構成されます。このタスクフォースは新機能を認識して評価し、変更管理委員会にそれらを提案します。ドメインのモデルを詳細に定義することに加え、関わりそうな技術トレンドも特定します。そしてアーキテクチャも調査します。しかし、最も重要なタスクはプロダクトライン開発によって各プロジェクトが恩恵を受けるようにすることです。
プロダクトライン開発に適した変更管理ですか?
たとえ素晴らしいアーキテクチャがあってpure::variantsのような優れたプロダクトライン開発支援ツールを有していても、絶え間ない変更に対して適切な扱いができないなら全ては泡と化します。では、プロダクトラインで変更管理の取り組みに重要な特性とは何でしょうか?
(1) 変更要求から影響を受ける製品群にトレースできること
もし変更管理が、単に変更があることを通告するだけでその変更要求がどの既存製品に関連するか記録しないものなら、それはプロダクトライン開発には適しません。単純なケースは単一の製品のみが影響を受けるか全製品がその対象となるのかの二つですが、製品のサブセットが影響を受けることも多くあります。影響を受ける製品サブセットを知ることで、多くの場合(特にテストの)工数や意思疎通でのオーバーヘッドを最小にできます。この情報がないと、単一製品にだけ影響すると明確になるまで、すべての問題が全製品にわたって通達されなければならないことになります。
(2) コア資産からそれを用いる製品にトレースできること
一つの修正を目的にした変更要求によってコア資産を変更するならば、それによって影響を受ける製品を特定できなければならない。さもなければ非常に多くの製品のテストをすることになり、工数が掛かって製品リリースが遅延してしまいます。あるいは(その資産を使っていないので)問題の影響のない出荷製品に対してリコールするような事態に陥り、ビジネスへの悪影響は計り知れません。
(3) 変更要求から関係するコア資産にトレースできること
多くの場合、変更から既存製品にトレースできることだけでは不十分です。変更管理に問題を登録した後に新製品を作ってビルドすることを想像してください、コア資産のどれが問題の影響を受けるかを特定でき、(2) のようにそれらを使用する各製品にトレースすることができるなら、新たに開発された製品に影響するかもしれない問題をトレースできるでしょう。
(2)と(3)がうまくできれば、製品群の一覧はほぼ自動で生成できるようになるので、明らかに(1)はそれほど大きな課題ではなくなります。
これらの特性必須で、もしなければプロダクトラインの取り組みが完全に失敗する運命にあるというわけではありません。しかしながら、プロダクトライン開発の初期段階が上手くいって、多くの変更要求を含む派生製品が多く生み出されるようになった時に、もし正しい変更管理ができなければ当初の成功は直ちに裏目となってしまいます。事前に備えることが賢明なのです。
プロダクトライン開発の変更管理プロセス例
広範に異なるドメインとプロダクトラインに対する取組みの多様性のため、単一で全てにフィットする変更管理プロセスはありません。しかし、以下に説明するプロセス例は大抵のプロダクトラインに適用できるものです。コアプロセスを紹介した後、多くのケースでこのプロセスが十分単純化できることを説明します。
シナリオはプロダクトライン内で多くの製品が並行して開発やメンテナンスされていることを前提としています。製品は、ユーザーの観点で見えるフィーチャ/機能で定義され、共有されるコア資産といくつかの製品特有の資産で構築されます。通常、顧客/ユーザーは、多くの場合は影響を受ける機能を挙げて、特定の製品の欠陥を報告します。同様に、フィーチャの追加・変更・削除という変更要求は、多くの場合製品顧客/ユーザーに関わるものですが、他にもプロダクトラインマネジメント委員会などから特定製品に関わらない要求も来ます。課題への対応に対する状態やワークフローは、多くの課題管理ツールで標準的なもの(「新規」、「割当済」、「修正済」、「検証済」などの状態と課題間の単純な依存関係)です。(簡単な)課題管理ツールの例としてはBugzillaを見てください。
ここで「課題」という用語は、欠陥やアクションアイテム、変更要求などを表す一般的なものとして使用しています。
一つの製品欠陥に対して一つの課題を生成するだけという単一システムの取組みがプロダクトラインのシナリオとはならないことは、共有されるコア資産の一つ欠陥は複数の製品に影響するということから明らかです。課題を単一の製品だけでなく影響をこうむる全製品へリンクすることはより良いことですが、制約もあります:その課題は、対応する修正が機能する全製品において修正済であり、動作することが検証済となるまで完了できないことです。もし修正に対する検証作業が製品群に対して別々に実施される場合、いくつかの製品には修正が正しく動作することが検証されるのに、他の製品にはその情報が行き渡らないことがあります。「部分的に検証済み」や検証済み製品のリストを課題に記録するなど、課題の何らかの中間状態が必要になるため、これは課題管理システムで記録するのが面倒です。 それでも、すべての製品について修正が機能することが確認されていない限り、問題は正式に「クローズ」状態にはないため、正常に検証された一部の製品のリリースには問題があります。
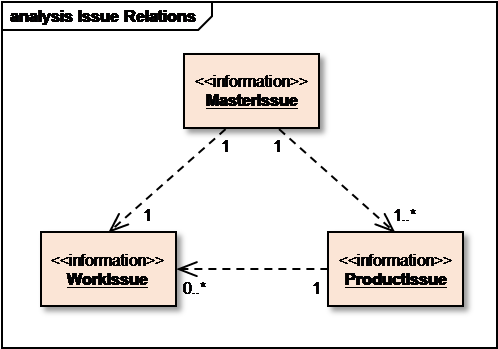
この問題を解決するのに、一つの課題を関連する課題のタイプに分割する方法があります。WorkIssueは課題解決の進捗を記録するために、ProductIssueは個々の製品に関して課題の状態を記録するために用います。すなわち各ProductIssueは一つの製品にリンクされます。ProductIssue の目的は主に、製品に対する課題の関連性の検証とその製品への課題解決策の適正さをトレースすることです。そして大事なのが、MasterIssueを用いてWorkIssueと全てのProductIssueを一つにまとめることです。なぜなら、課題はWorkIssueと関連した全てのProductIssueの両方が完了となって始めて完全に完了とできることになるからです。MasterIssueは、依存するすべての課題の(うまくいった)解決法に依存しますが、その事実を記録するために使用されます。
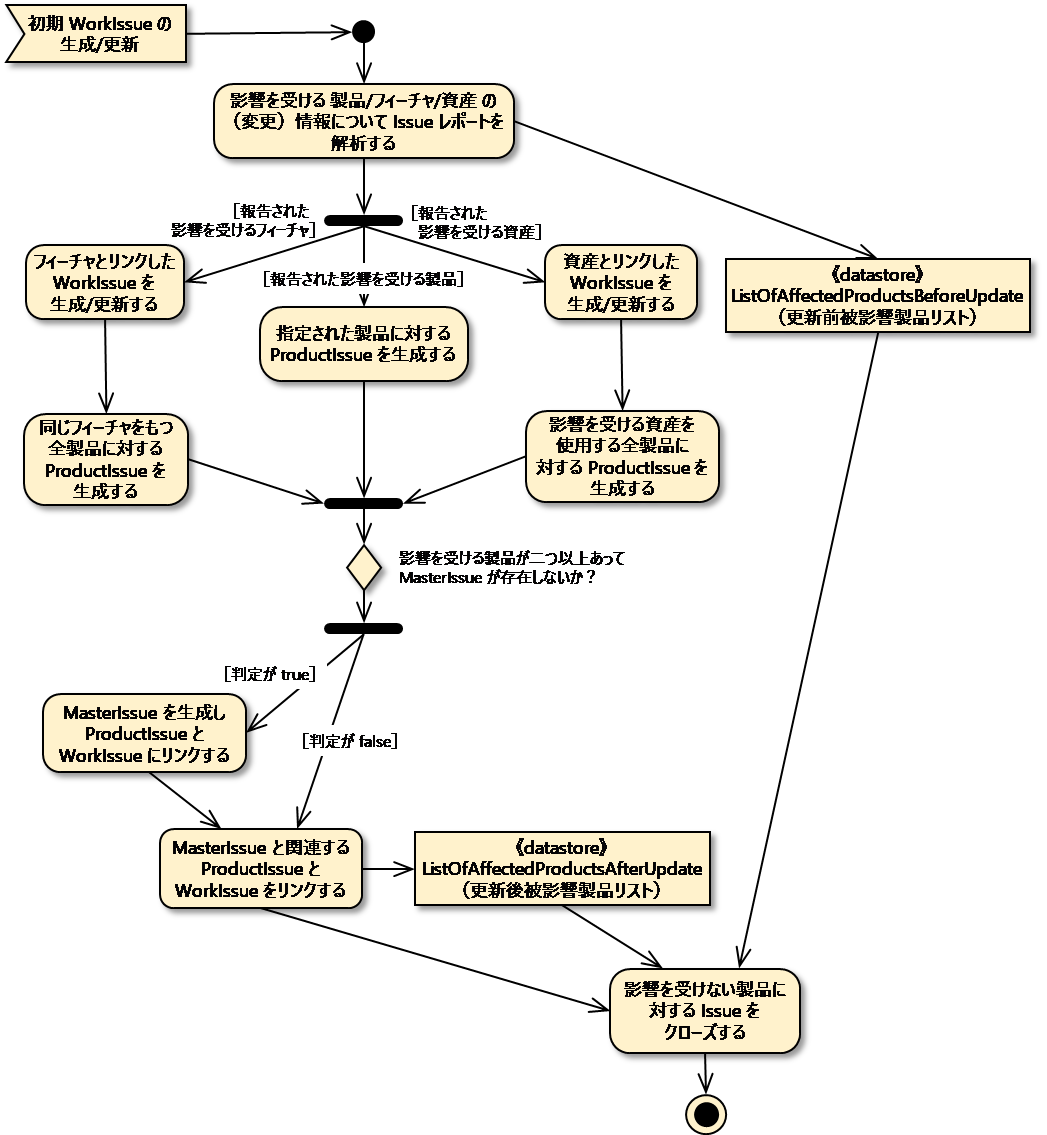
変更管理のアクティビティ図 課題生成/課題更新
上のアクティビティ図で最初の作業課題が生成されてからの手順を示しています。課題に対する初期確認から得られる情報に基づいて関連の課題が生成されます。最初の課題はWorkIssueになります。簡単にするためにMasterIssueはProductIssueがある場合(すなわち、課題の影響をこうむる複数の製品がある場合)にのみ生成されるようにします。WorkIssueへの変更がある場合はいつでも同じプロセスが実施されます。
このアプローチは様々なゴールをサポートします:共有される資産への課題修正と、それを製品群に反映させることを適正にモニタすることです。(単一製品の開発とほとんど同じなので)一つの製品だけが関わるなら、これは単純で、そして品質に対して妥協なしの迅速さが求められるような製品ごとに同じ課題でも異なる状態を持たせることができます。
もちろん、そのようなワークフローを実施するには変更・修正のインパクトを評価できる適切なツールのサポートと状態の変更への対処の自動化など(例えば不要な手作業を削除する工夫)も必要です。pure::variantsはもちろん、それに役立つよう製品間にまたがる評価を支援して課題の状態を視覚化するための優れた表示機能などを持っています。
最後に
もちろん本稿は開発チーム固有に変更管理の課題を扱う手法の完全な青写真ではありませんが、注意すべきことへの何らかのヒントになっています。場合によってはワークフローの単純化も可能です:例えば全製品の同時リリースを実施しているなら、関連製品ごとで個々の状態に対処する必要はありません。
変更管理の課題はプロダクトラインの研究や文献ではまだよく発表されていないように思えます。それらについて実践者や研究者から知りたいと思っていますので、是非ともアイデアやコンセプトを発表いただいて皆で共有しましょう。
原文:Moving targets – Change Management for Software Product Lines
5.何が違うのか? プロダクトラインの構成管理の詳細
Article (5) What’s the difference? A Closer Look at Configuration Management for Product Lines
プロダクトラインの構成管理は複雑な問題になる可能性があるでしょうか? と聞かれると、はい間違いなくそうです!
ただ複雑な問題でなければなりませんか?と聞かれれば、いいえ、そんなことは全然ありません!
これまでの記事で、バリアントとバージョンの違いやクローン&オウンが招くプロダクトブッシュが、(取り組み当初はシンプルで安くつくように見える、最も普及した方法であるが)最も推奨される再利用のアプローチではないことについて述べてきました。今回は残っている事項:適切なプロダクトライン開発のための構成管理について紹介します。
正しく実施していれば、単一のシステム開発とプロダクトライン開発で構成管理に(重要な)違いはないということは、間違いありません。しかしこれだけでは十分な説明とは言えないので、詳しく見ていきましょう。
まず始めにプロダクトラインで構成管理を行うときに犯し得る最大の間違いについて指摘します。それは構成管理をバリアビリティとバリアントの管理システムに誤用することです。一般に、構成管理システム(バージョン管理システムとも)は、ブランチングとして知られる概念を提供します。それは、一連のセットからなる成果物のコピーを作り、そのオリジナルとは別個に変更するということです。ブランチングの適正な使用法は後で述べるようにいろいろありますが、非常に不適切な使用法が一つあります:それは一連のセットからなる再利用資産のバリエーションを管理する中核的なコンセプトとしてブランチングを用いることです。もしバリエーションが最初にブランチを作ることで扱われて、以降オリジナルとブランチされた成果物のいずれかを使うことで製品を区別するようになると、それ以外の再利用の手法と比較して多くの場合(不必要な)オーバーヘッドに見舞われることになります。なぜなら一般にブランチされた成果物は(話を単純にするため一つのファイルがブランチされたとして)、全てが変更されるわけではなく、オリジナルから変更されないままの箇所を(多くの場合、非常に大きく)含むからです。
ブランチかオリジナルかで問題が見つかった(ここではオリジナル側を仮定)とします。修正が行われてバージョン管理システムにチェックインされ、ここまではOKです。さてブランチに何か行わなければなりません。第一に、ある製品に使用されているブランチされた成果物にも修正を考慮しなければならないことに注意するべきです。バージョン管理システムによっては、変更がいくつものブランチにある場合に関連するブランチされた成果物を探す支援機能があるでしょう。それは良さそうです。ブランチとオリジナル両方で同じに見えるファイルのどこかで修正が見つかった場合、単純に修正をコピーするだけで簡単に済みそうであるが、どうでしょう。
しかし、ちょっと待ってください! ブランチ内でファイルのこの部分が変更可能であることを知りえるでしょうか? ここでバリエーションの管理されている粒度はファイルなので、オリジナルとブランチされたファイル内で同一の実体(ファイルの行数など)が同じである(バリエーションの部分ではなくて共有されるべきもの)と考えるのか、あるいは一部の実体は(ブランチングの時点で意図された)バリエーションに属していて変更できないのかを(バージョン管理システムでも人でも)がたやすく知る方法はないのです。この例としては、バッファサイズのような構成のための定数パラメータがあるでしょう。もしこのパラメータがオリジナルのアルゴリズムとブランチ内で修正後のアルゴリズムの両方で使用されていたら、オリジナル側でのその変更によって、ブランチされたコピー内で修正済みのアルゴリズムの同じ定数の変更が必要になるか、それどころかその変更が可能であるかさえ分からないのです。そこで、修正のどの部分がブランチされた成果物に適応されるのかをチェックしなければなりません。たとえその修正がバージョン管理上、技術的には矛盾を起こさないように見えていても必要です。適正に自動化されたテストスイートがある場合は、マージされた成果物を含む全ての製品をテストして影響をこうむらないことを確かめるべきでしょう。そうでない場合(自動化テストスイートが不可能なドメインもあります)、それは基本的には人手の当て推量になってしまいます。
このことはブランチされた成果物が、共有コードを(ほとんど)含むことなくバリエーションだけで成り立っている場合には当てはまりません。つまりバリエーションがファイルの粒度で適切にカプセル化されているということです。このような場合、一つのファイルがオリジナルとブランチされたコピー間で共有されることもされないこともあります。そして全てのファイルに対してそのことが分かれば、共有される/されないファイルセットの両方に含まれる変更集合の問題に対処するのみです。これらを共有されるファイル群だけに関わる変更集合と単一ブランチに固有の変更集合に分散することが必要です。共有されるファイル群への変更集合に対しては、変更は共有される全てのインスタンスで行われるべきです。もし後日、以前にブランチされたコピーからさらに枝分かれしてコピーを生成する場合、その枝分かれのコピーが元のブランチされたコピーと共有されるが、オリジナルとは共有されない場合、それらをバージョンコントロールシステム内で追跡することは複雑なものになります。
ここまでは一つのファイルを例にしてきましたが、実際は数百・数千に上るファイルで、この問題が起こります。そしてブランチが多いと、変更ごとに各ブランチで同じルーチンを実行することが必要なので、作業は劇的に増加します。共有成果物とブランチが少なければ大丈夫かもしれませんが、共有成果物が少ないということは再利用できる成果物の数を制限することになりますし、ブランチはバリエーション数の制限になります。図にするとこのシナリオの複雑さが見えてきます:典型的なバージョン管理システムから出力される(簡略化した)ブランチ/マージのログ(左から右の時系列)を使って、7つの製品(P1~P7)が既存システムのクローン作製でよくある「ブランチ&マージ」戦略で実装され、各々独自にメンテナンスされます。全てのブランチされたインスタンスにきちんと変更を同期させ続けることは非常に難しい作業であることは明らかです。マージするために必要となる作業量から、多くの場合「二つの製品間」のみでマージされる(いくつかのパーツを他方の製品から取ってくる)ことになります。これでは体系的な再利用とは言えそうにありません。
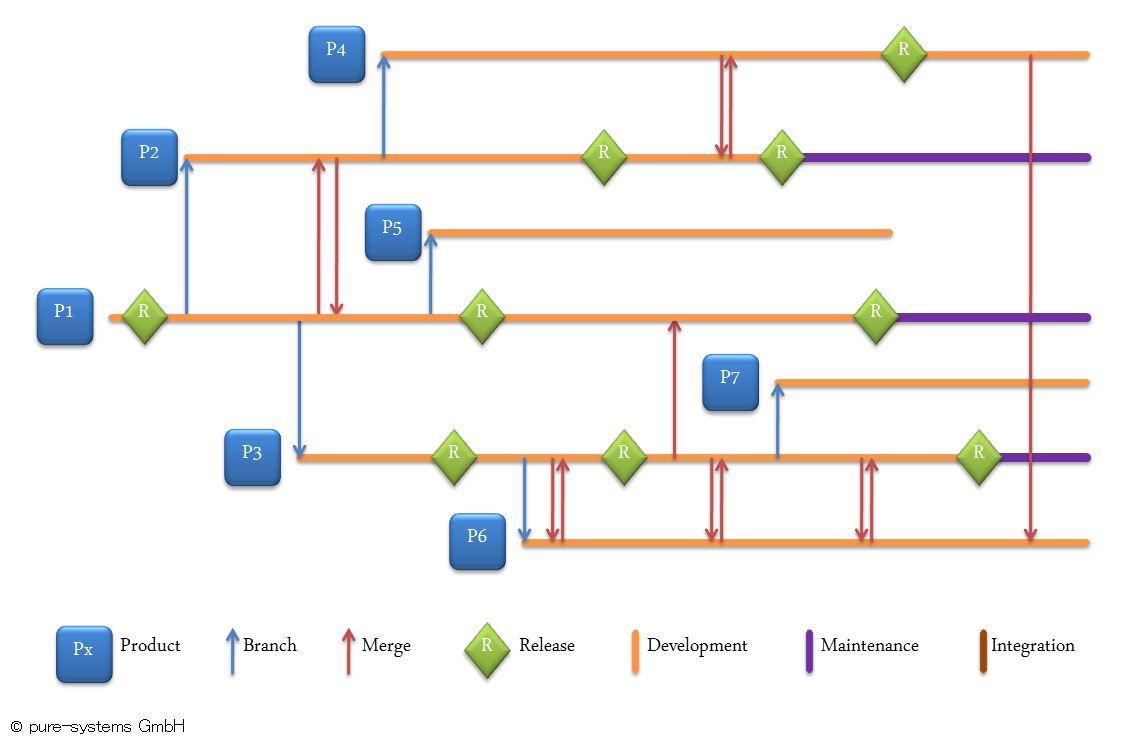
要するに、バージョン管理される資産の粒度がバリエーションの粒度と同等でない限り、バージョン管理内のブランチングはバリエーションポイントの表現には向いていないということです。たとえバージョン管理システムのベンダーがバリエーション管理にも使えますと言っても、粒度のミスマッチがあることに用心してください。そしてファイルの成果物に関しては、粒度のミスマッチはほとんど不可避です。誤解しないでいただきたいのですが、成果物への変更をその寿命にわたって追跡するために適正なバージョン管理ツールを使うべきであるが、バリアビリティとバリアントの管理は一緒にはできないということです。バリアビリティは、バリアントに使用可能なものと特定の時点で使用中のものを、別個の直行する次元で表現するものです。
プロダクトライン開発でどのようなブランチが良いかお迷いでしたら、単一の製品開発では単純に次の二点です:短期的に独立した開発活動をメインブランチから分離する(フィーチャブランチ)と、メインブランチで進行中の変更から(直ぐの)リリースを切り離す(リリースブランチ)です。これら両方のコンセプトについての良い説明は、無償のSubversion eBook にあります(“trunk”を“main development branch”として読み替える以外、記述はほぼSubversionに依存しません)。これらのコンセプトを適応すれば、よりわかりやすく良い図式となります。開発のメインストリームより上側のブランチはリリースのためのもので、下側のものは新機能開発用です。一般に、ブランチはより短期間であり、マージはほとんど開発側のブランチから開発のメインストリームへと行われて、リリースブランチから/それへのものはほとんどありません。このアプローチはわかりやすい図式になるだけではなく、真の再利用が容易にできるようにもなります。
下図は、上図のP(製品)の代わりにV1~V4(バリアント)が共通のベースから派生されている状況です。共有ベースからのバリアントの実際の派生は、通常なんらかのコンフィグレーションかpure::variants のような適正なバリアビリティとバリアント管理ツールによって、独立した活動として実施されます。この派生/インスタンス化の活動がバージョン管理された成果物の上で行われることがポイントで、バージョン管理システムはインスタンスの記録に使われはしますが、バリエーションポイントの仕組みは提供しません。
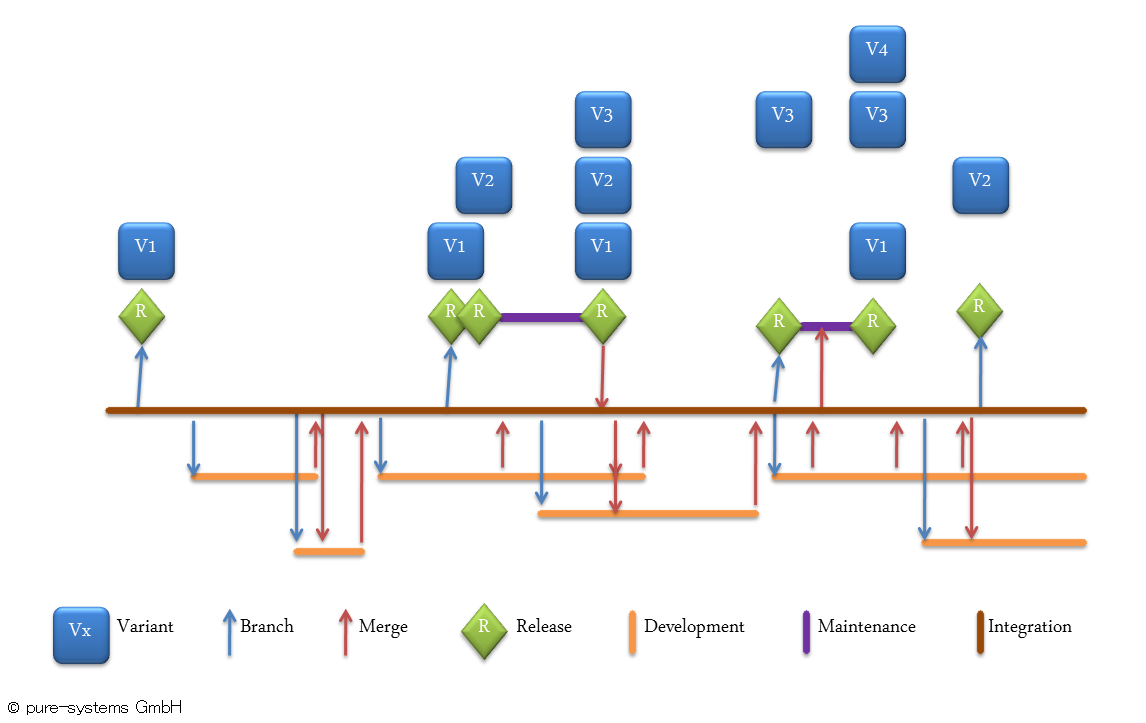
以上から最初の主張であった、もしバライアビリティとバリアントの表現がバージョン管理で行われていなければ(これは名案:上記参考)、プロダクトライン開発でバージョン管理に特別なことは無い。(より多くのユーザと変更によるパフォーマンスやスケーラビリティの課題があるにしても)
原文:What’s the difference? A Closer Look at Configuration Management for Product Lines
6.プロダクトラインエンジニアリングにおける
リリース、開発、保守の戦略:Part 1 製品開発組織
Article (6) Strategies for Releases, Development, and Maintenance in Product Line Engineering: Part 1 Product Development Organization
プロダクトライン開発には極めて多彩な取組みの選択肢がある。例えば開発されるプロダクトラインのドメインによって異なった製品リリース、開発、メンテナンスの戦略があります。取り得る選択肢を知り、最も適したものを注意深く選択することでプロダクトラインエンジニアリング開発を成功に導くことができます。以下でいくつかの基本的な戦略の候補とユースケースを手短に紹介します。
製品の開発戦略
共同開発(Joint Development)、並行開発(Parallel Development)、逐次開発(One by One Development)について紹介します。

共同開発戦略では、製品群や再利用可能な(コア)資産、そして製品ごとの固有資産は共同で開発されます。組織は、プロダクトライン全体に集中して一つの大きな仮想チームとしての役割を演じます。この戦略の実施にあたっては多くの場合、なんでもこなすゼネラリストのエンジニアからなる比較的小さなチームか、あるいは大きなシステムにはそのシステムの異なるパーツごとのスペシャリストのチームを擁することになります。
このスペシャリストのチームあるいは個々のゼネラリストは、開発中のいくつか、あるいは全製品をある時点でリリースするために協調します(次の記事「コア資産と製品のリリース戦略」を参照)。各チームやそのメンバー達は基本的に適切な意思伝達を行って協調できるので、たいへん効率的です。
このことは一般に、その製品ビジネスがあるレベルの複雑さになるまでは当てはまります。もし並行して開発される製品数が非常に多くなったり、製品ごとで再利用されない部分の比率が大きくなったりすると、基盤(全体に対する再利用資産)を担うチームと特定製品/製品グループを担うチームへの分割が要求されるようになります。
それでも、この戦略はプロダクトライン全体に重点を置くので、多くの場合複数の製品間で高い再利用率を得る非常に効率の良いプロダクトラインとなります。特に、既存機能の変更に対する調整作業は比較的少ない。なぜなら多くの変更要求が単一チームあるいは開発者の担当領域に関わって、それらの対立と依存が容易に検討し処理することができるからです。これは本質的に大抵の場合、プロダクトライン開発に最適の戦略です。しかし、この戦略をサポートするように開発組織を変化させることは容易ではありません。多くの場合プロジェクトマネージャにとって失うものがあります:このシナリオではリソースへの独占的なアクセス(すなわち権力)がなくなりやすいのです。
並行開発戦略と私が呼ぶ二つ目のシナリオでは、複数のプロジェクトチームがあり、それぞれ他のプロジェクトとは独立して、一つ以上の製品あるいは資産群を開発します。通常、各プロジェクトにはその製品ごとのリリーススケジュールや顧客があります。並行して開発している各チームの主な関心事は各製品のリリースであってプロダクトライン全体ではありません。
この場合、(多少の)コア資産開発ではしばしば共同開発を伴うこともありますが、最も極端な例では共同開発は全く行われません。再利用可能な資産さえも独立した製品チームで開発されるのです。そして新しい再利用機能や既存資産への変更の実装と優先付けの点から、意思疎通や協調、利益の対立に対する適切なマネジメントの必要性が大きくなります。
「従来の」プロダクトラインのアプローチでは、プロダクトライン資産の上に、(再利用資産の)共同開発と(製品/バリアントの)並行開発を、混成することが推奨されていたように思えます。それにより、ドメインエンジニアリングとアプリケーションエンジニアリングがはっきりと分離されることになりますが、これら両サイド間の意思疎通は制限されます。並行開発時に見られるのと同様に全チームがそれぞれ「あちら側とこちら側」といった具合になるからです。この意思疎通の制限には良い面と悪い面があります。良い面は製品チームが再利用資産の実装を要求するまでに何らかの敷居があることです。これは意思疎通の頻度と量に歯止めをかける。しかし、時にコア資産の開発において、プロジェクトにはユースケースがないのに前もって再利用資産が作られてしまうことや、要求がプロジェクトチームによって適切に協議されなかったことで役に立たない再利用資産が作られてしまうことがあります。もしくはコア資産開発チームに特定のユースケースに関わる知識が十分でないなどです。
しかし、本質的に製品プロジェクト内の開発はお金を出してくれる人(すなわち顧客)とより密接であるので、これが最も多く実施される戦略でもあります。
最後は非常にシンプルな「逐次」アプローチです。この場合、一つの製品を開発してその開発が終了すれば次の製品に進みます。基本的に二つ以上の製品を同時に開発することはありません。このシナリオはほとんどどのケースで縁がなさそうですが、明らかに最もシンプルなアプローチです。適応できる場合には、ある時点で単一の製品に明確に焦点をあてることができるので極めて効率良いものです。しかしながら旧製品のことを全く忘れても良いということではなく、通常は組織内の誰かがそれらの保守とサポートを受け持たなければなりません。もし逐次アプローチがクローン&オウン(既存製品のコピーを基に次製品を開発する)で行われるなら、旧製品に欠陥が見つかった場合に問題を引き起こすでしょう:祖先である以前の製品の1つで発生した問題に対する修正は、基本的には問題を発生させた製品から派生した各製品に対して数回実行する必要があるからです。次に紹介する製品メンテナンスの戦略でこの問題について分かりやすくお話しします。
原文:Strategies for Releases, Development, and Maintenance in Product Line Engineering: Part 1 Product Development Organization
7.プロダクトラインエンジニアリングにおける
リリース、開発、保守の戦略:Part 2 リリースと保守
Article (7) Strategies for Releases, Development, and Maintenance in Product Line Engineering: Part 2 Release and Maintenance
プロダクトライン開発の基本戦略である製品リリースと、開発、保守についての後編です。もちろん現実はここで紹介するほど単純ではありませんが、これらの戦略を基にして各組織で主となる取り組みを分類することができるでしょう。ここでは「コア資産の開発と製品/バリアントへの使用」に関する内部のコラボレーションと、「製品リリースと保守」に対する外部のコラボレーションと展開、の両方について紹介します。
コア資産のリリース戦略
前の記事では開発戦略を製品/プロジェクトとの関連で観察してきましたが、製品開発プロジェクトで使用されるコア資産に対する異なったリリース戦略について紹介します。

良く取られる戦略の一つにハートビートリリース(Heartbeat Release)があります。プロダクトラインの全てのコア資産は、短い、大体は定期的な周期でテストとリリースが同時に行われます。このことは、それぞれのドメインで変更が必要となるスピード次第であり、2週間に1回、または最大6ヶ月に1回のリリースであることを意味します。ある時点でリリースされる全ての資産は相互に動作するはずなので、これは良いアプローチです。これは依存関係の複雑さが少ないことを意味します。すなわち、製品はコア資産のハートビートリリースの一つに頼っているということです。これの問題は、製品への新しい機能を正式に使用できるまでにハートビートでリリースされるのを待たなければならないことです。このことで製品リリースやサポートなどの速度が損なわれてしまいます。もちろん顧客を満足させる方法もあります:もし少数の製品間で重大な欠陥が見つかれば、リリースブランチ(あるいはリリースタグ/ラベルを元にした追加のブランチ)で影響を受ける製品への修正を作り、テストして修正した製品を出荷して、その修正を次のコア資産の「公開」リリースに反映させます。このような順序を乱す修正がリリース間で頻発するなら、ハートビートのタイミングを短くすることやコア資産の品質保証を向上することが必要になります。
速度を重視するなら、独立リリース(Independent Release)と呼ばれる戦略です。システムの個別部品、一つのコア資産、あるいは関連するコア資産群は、多くの変更が統合されてその資産のサブセットを担うチームが十分リリースに値する(すなわち製品開発に使用できる)と判断した後、リリースされます。これはプロダクトラインの資産への部分的なアップデートを許すので当然変更の速度が増すことになって、より複雑な依存関係を持つことになります。コア資産群は非常に多くの独立したリリースバージョンを持つことがあり、かつ異なる出荷製品の異なったリリースに用いられるかもしれません。これは特に、並行開発戦略を採用していて頻繁に非同期の製品リリース(後述します)を行う場合に起こりえることです。極端な場合、各製品が独自のバージョンからなるコア資産を持つことになり、そうなると問題への修正は途方もなく遅くなるかもしれません。なぜなら、全ての異なるバージョンが修正されて再テストされなければならないか、あるいは製品すべてが影響を受ける資産の新リリースへのアップグレードを必要(さらに基本的に、最悪はそれら全てへのテストも必要)とするからです。
もっと極端な戦略は、継続リリース(Continuous Release)です。この戦略ではコア資産のリリースそのものはありません。主となる一つの開発ストリームがあり、全てのコア資産は最新版の開発とともに絶え間なくアップデートされます。各製品開発は通常、コア資産の最新のものをベースとします。リリースに向けた成熟段階でのみ、これら製品は主たる開発の流れから個別の流れにブランチします。これによって製品は更なる開発から切り離されますが、それらの進捗からの影響を多くは受けずに完成させることができます。このアプローチでは管理できそうにないと感じる人がいるかもしれませんが、大規模な開発組織でも非常に上手くいっている事例があります。例えば、HP社インクジェットプリンターのOwenプロダクトラインはこの手法で開発されています。(“Dynamic Complexity and the Owen Firmware Product Line Program” by Holt Mebane and Joni T. Ohta)
当然この戦略は、確固たる共同開発のアプローチと合わせて行われ、かつ製品リリースへの成熟段階が相対的に短い場合に最上の結果を得ます。深刻なメンテナンスを要しない製品に適しています。たとえそれが製品群とコア資産間でかなり複雑な依存関係を生み出したとしても、この戦略はメンテナンスが必要な製品に使用できます。リリースされた製品を「リベース」する労力は十分低くあるべきで、メンテナンス状態の製品数も少なくするべきです。そして、問題のある製品群を開発ストリームのヘッドに移動させてそれらの新しいリリースブランチを作るだけです。
製品のリリース戦略
コア資産のリリース戦略(これは内部プロセスです)と同様、プロダクトラインから生産される製品個々にも異なるリリース戦略があります。基本的には、同期・非同期の二つのリリース戦略として捉えます。

同期的製品リリース(Synchronous Product Release)戦略では、(ほとんど)全てのアクティブな製品が同時に市場にリリースされます。これは例えば(pure::variantsのような)多くの市販ソフトウエアツールの市場出荷と同じ方式です。 この方法は依存関係を単純にして、テスト(特に単体テスト)と検証作業の軽減に寄与します。なぜなら多くのテストを複数回実行する必要がなくなるからです。もしテスト入力とテストされたコンポーネントの両方が、他製品で既にテストされたものと同じであれば同じことを繰り返す必要はありません。しかし、この戦略ではテストと認証に開発リソース消費のピークが生じます。特に製品ごとに人手で、実行に長時間を要するテストが必要な場合、恐らくそのピークは高すぎるものになるでしょう。
非同期的製品リリース(Asynchronous Product Release)戦略では各製品のリリース時期は個々に任せられます。この戦略は、さまざまな顧客やユーザーがそれぞれ大きく異なる間隔で要求への対処を求めるような場合に有効です。また、製品リリース前のテスト部門での作業負荷などを軽減できます。一方、同期的リリースなら、全製品は同じリリースのコア資産をベースにしているので、一般に保守工数の軽減に功を奏しますが、これは非同期的リリースでは保証できません。
ここで言うリリースとは顧客へ製品を実際に出荷することとは限らないことに注意してください。製品が出荷できる状態になっただけのことも含まれます。多くの場合、物流の工数が発生するので新しい製品リリースが頻繁に提供されることは望まれません。例えば、何千・何百万といった組込み製品に搭載されるフラッシュメモリのアップデートなどのような場合などです。
すべての製品が自動的に新しいリリースを得ることができない場合でも、すべての製品のリリースを自動的に準備することは、すべての製品に最新の修正を適用し、これをオンデマンドで使用するための製品メンテナンス戦略と見なすことができます。以下で保守戦略について述べます。
製品の保守戦略
最後に、メンテナンスやサポートという製品の市場出荷後のフェーズについてお話します。ここでもまた、基本的に二つの選択肢があります。
一つ目はイベント誘起型保守(Event Triggered Maintenance)で、ある製品で欠陥が報告されると、この製品(および関連する製品)をアップデートして終わりというものです。つまり保守期間では、ある問題の影響を受ける製品だけを再ビルドし、テストしてリリースします。ここで追加の選択肢として、旧コア資産リリースに基づいて問題修正をするのか、旧製品を新しい(多分最新の)コア資産リリースに移行するのかがあります。
別の方法は継続的保守(Continuous Maintenance)で、旧製品の新プラットフォームリリースへの更新は、新製品のリリースと同じ方法で行われます。これは基本的に、以前リリースした製品と新しく開発された製品とを区別することなく、すべて等しく扱うことを意味します。これは、いつでも全製品にリリースしたものが反映されるので、飛躍的にサポート工数を削減できます。ただこれは、リリースが用意される全ての製品を出荷しないといけないということではありません。多くの顧客は、問題に直面していないときはなおさらですが、頻繁にわたるリリースを望みません。一方で、顧客が望むなら、修正された製品を直ちに出荷する準備ができているということです。
多くの場合、この二つのアプローチの組み合わせが最も賢明な選択となります:新しい製品には継続的保守で最新版を提供し、市場でしかるべき期間が経過した旧製品であれば、イベント誘起型保守に移行して保守の終了を待つことになります。
Putting it together
上述してきた選択肢によって、三つの代替(alternative)がある二つのグループと、二つの代替(alternative)がある二つのグループを合わせた、フィーチャモデルを構成することができます。
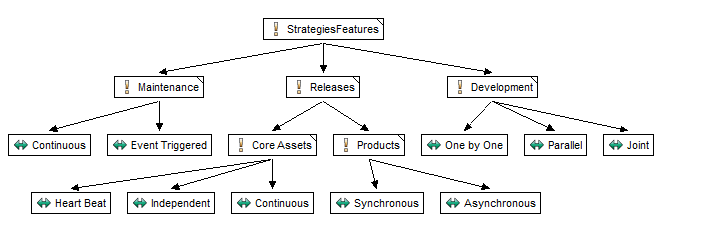
これから3×3×2×2 = 36通りの選択肢が取れます。どのアプローチを取るべきかの正解はありません。一般には製品開発のビジネス上の戦略として最もシンプルな手法を選択します。開発組織の全体的な規模は重要な懸案事項となる。小さな組織なら、協調や意思疎通の点から少数のチームが非常に有益です。大きな組織なら、ドメインエンジニアリングと製品開発プロジェクトを分離することによって、個々のプロジェクトの要求から、コア資産開発を健全な状態に保つ適正な(望ましい)壁を設け、より良いバランスを保ちます。
原文:Strategies for Releases, Development, and Maintenance in Product Line Engineering: Part 2 Release and Maintenance
セミナー報告・資料公開
ASF2022 講演:プロダクトライン開発
バリアント管理支援ツールから習う賢人の知恵
派生製品開発で継続して行われる改善や工夫は、上手に情報管理して役立てたい。そうすることで、複雑さが増大する製品の開発を加速すると同時に、品質改善や、高度なトレーサビリティによる保守性向上を期待できる。そのためのプロダクトライン開発のバリアント管理支援ツールは、欧州車載機器開発の最前線で活用されるなか、顧客の知恵と工夫が機能として組み込まれて進化している。本講演では、これら賢人の知恵ともいえる機能を紹介することを通じて、プロダクトライン開発の現実的な実現方法を調査される方や、今後検討したい方が、その取り組みの足掛かりになる情報を提供する。

ASF2021 講演:プロダクトライン開発
プロダクトラインエンジニアリングの未来予測
テクノロジーの進化はPLEに何をもたらすか? PLEが直面する様々な課題は、最新のテクノロジーで克服して、新たな機会に転じることができる。欧州車載システムの最前線から、少し高いレベルの視点で、CASE時代のPLEの課題と可能性を展望する。
スパークスシステムズ ジャパン
連携セミナー
「プロダクトライン開発のバリアント管理について」
プロダクトライン開発では、バリアント管理を通じて、製品系列で共有する資産を体系的に再利用します。これは派生開発で継続して行われる改善や工夫を、上手に情報管理して役立てるということです。そうすることで、複雑さが増大する製品開発を加速すると同時に、品質が改善され、トレーサビリティが高度に確保でき保守性も向上するなどの相乗効果も得られます。
このセミナーでは、プロダクトライン開発とバリアント管理について説明します。Enterprise Architectとバリアント管理ツールとの連携もデモで紹介します。既にプロダクトライン開発を知っていて現実的な実現方法を知りたい方だけでなく、プロダクトライン開発を知らない人もぜひご参加ください。派生製品の開発で、以下のような苦労をされていないでしょうか?
- コードを再利用するつもりが、同じバグの対応を何度も繰り返すことに
- ブランチとバージョンの組合せ爆発ですべてが複雑になり、メンテナンスも困難に
- 顧客からのバックポート要求も多い
プロダクトライン開発はこのような状況を改善する強力な支援となります

セミナー資料公開中

